欢迎来到@ZhangHaipeng主页!
让知识成为信仰,让优秀成为习惯-
2025-09-10
-
python pyinstaller 安装和使用教程
在创建了独立应用(自包含该应用的依赖包)之后,还可以使用 PyInstaller 将 Python 程序生成可直接运行的程序,这个程序就可以被分发到对应的 Windows 或 Mac OS X 平台上运行。
安装 PyInstalle
Python 默认并不包含 PyInstaller 模块,因此需要自行安装 PyInstaller 模块。
安装 PyInstaller 模块与安装其他 Python 模块一样,使用 pip 命令安装即可。在命令行输入如下命令:
pip install pyinstaller强烈建议使用 pip 在线安装的方式来安装 PyInstaller 模块,不要使用离线包的方式来安装,因为 PyInstaller 模块还依赖其他模块,pip 在安装 PyInstaller 模块时会先安装它的依赖模块。
运行上面命令,应该看到如下输出结果:
Successfully installed pyinstaller-x.x.x其中的 x.x.x 代表 PyInstaller 的版本。
在 PyInstaller 模块安装成功之后,在 Python 的安装目录下的
Scripts(D:\Python\Python36\Scripts)目录下会增加一个pyinstaller.exe程序,接下来就可以使用该工具将 Python 程序生成 EXE 程序了。PyInstaller生成可执行程序
PyInstaller 工具的命令语法如下:
pyinstaller 选项 Python 源文件不管这个 Python 应用是单文件的应用,还是多文件的应用,只要在使用 pyinstaller 命令时编译作为程序入口的 Python 程序即可。
PyInstaller工具是跨平台的,它既可以在 Windows平台上使用,也可以在 Mac OS X 平台上运行。在不同的平台上使用 PyInstaller 工具的方法是一样的,它们支持的选项也是一样的。下面先创建一个 app 目录,在该目录下创建一个
app.py文件,文件中包含如下代码:from say_hello import * def main(): print('程序开始执行') print(say_hello('孙悟空')) # 增加调用main()函数 if __name__ == '__main__': main()接下来使用命令行工具进入到此 app 目录下,执行如下命令:
pyinstaller -F app.py执行上面命令,将看到详细的生成过程。当生成完成后,将会在此 app 目录下看到多了一个 dist 目录,并在该目录下看到有一个 app.exe 文件,这就是使用 PyInstaller 工具生成的 EXE 程序。
在命令行窗口中进入 dist 目录下,在该目录执行 app.exe ,将会看到该程序生成如下输出结果:
程序开始执行 孙悟空,您好!由于该程序没有图形用户界面,因此如果读者试图通过双击来运行该程序,则只能看到程序窗口一闪就消失了,这样将无法看到该程序的输出结果。
在上面命令中使用了
-F选项,该选项指定生成单独的 EXE 文件,因此,在 dist 目录下生成了一个单独的大约为 6MB 的 app.exe 文件(在 Mac OS X 平台上生成的文件就叫 app,没有后缀);与 -F 选项对应的是 -D 选项(默认选项),该选项指定生成一个目录(包含多个文件)来作为程序。下面先将 PyInstaller 工具在 app 目录下生成的 build、dist 目录删除,并将 app.spec 文件也删除,然后使用如下命令来生成 EXE 文件。
pyinstaller -D app.py执行上面命令,将看到详细的生成过程。当生成完成后,将会在 app 目录下看到多了一个 dist 目录,并在该目录下看到有一个 app 子目录,在该子目录下包含了大量 .dll 文件和 .pyz 文件,它们都是 app.exe 程序的支撑文件。在命令行窗口中运行该 app.exe 程序,同样可以看到与前一个 app.exe 程序相同的输出结果。
PyInstaller 不仅支持
-F、-D选项,而且也支持如表 1 所示的常用选项。表 1 PyInstaller 支持的常用选项
-h,–help 查看该模块的帮助信息 -F,-onefile 产生单个的可执行文件 -D,–onedir 产生一个目录(包含多个文件)作为可执行程序 -a,–ascii 不包含 Unicode 字符集支持 -d,–debug 产生 debug 版本的可执行文件 -w,–windowed,–noconsolc 指定程序运行时不显示命令行窗口(仅对 Windows 有效) -c,–nowindowed,–console 指定使用命令行窗口运行程序(仅对 Windows 有效) -o DIR,–out=DIR 指定 spec 文件的生成目录。如果没有指定,则默认使用当前目录来生成 spec 文件 -p DIR,–path=DIR 设置 Python 导入模块的路径(和设置 PYTHONPATH 环境变量的作用相似)。也可使用路径分隔符(Windows 使用分号,Linux 使用冒号)来分隔多个路径 -n NAME,–name=NAME 指定项目(产生的 spec)名字。如果省略该选项,那么第一个脚本的主文件名将作为 spec 的名字 在表 1 中列出的只是 PyInstaller 模块所支持的常用选项,如果需要了解 PyInstaller 选项的详细信息,则可通过 pyinstaller -h 来查看。下面再创建一个带图形用户界面,可以访问MySQL数据库的应用程序。
在 app 当前所在目录再创建一个 dbapp 目录,并在该目录下创建 Python 程序,其中 exec_select.py 程序负责查询数据,main.py 程序负责创建图形用户界面来显示查询结果。
exec_select.py 文件包含的代码如下:
# 导入访问MySQL的模块 import mysql.connector def query_db(): # ①、连接数据库 conn = conn = mysql.connector.connect(user='root', password='32147', host='localhost', port='3306', database='python', use_unicode=True) # ②、获取游标 c = conn.cursor() # ③、调用执行select语句查询数据 c.execute('select * from user_tb where user_id > %s', (2,)) # 通过游标的description属性获取列信息 description = c.description # 使用fetchall获取游标中的所有结果集 rows = c.fetchall() # ④、关闭游标 c.close() # ⑤、关闭连接 conn.close() return description, rowsmian.py 文件包含的代码如下:
from exec_select import * from tkinter import * def main(): description, rows = query_db() # 创建窗口 win = Tk() win.title('数据库查询') # 通过description获取列信息 for i, col in enumerate(description): lb = Button(win, text=col[0], padx=50, pady=6) lb.grid(row=0, column=i) # 直接使用for循环查询得到的结果集 for i, row in enumerate(rows): for j in range(len(row)): en = Label(win, text=row[j]) en.grid(row=i+1, column=j) win.mainloop() if __name__ == '__main__': main()通过命令行工具进入 dbapp 目录下,在该目录下执行如下命令:
Pyinstaller -F -w main.py上面命令中的
-F选项指定生成单个的可执行程序,-w 选项指定生成图形用户界面程序(不需要命令行界面)。运行上面命令,该工具同样在 dbapp 目录下生成了一个 dist 子目录,并在该子目录下生成了一个 main.exe 文件。直接双击运行 `main.exe` 程序(该程序有图形用户界面,因此可以双击运行),读者可自行查看运行结果。项目打包 使用虚拟环境,安装所需最小资源的包
pyinstaller -F -c -i main.ico --onefile main.py-i: 添加exe 图标 -c 添加打开cmd窗口
-
人工智能的诞生
人工智能的诞生
* 四位学者1955年提出了人工智能这一术语及研究范畴 > 1.1 John McCarthy (时任Dartmouth 数学系助理教授1971度图灵奖获得者) > 1.2 Marvin Lee Minsky (时任哈佛大学数学系和神经学系Junior Fellow, 1969年度图灵奖获得者) > 1.3 Claude Shannon (Bell Lab, 信息理论之父) > 1.4 Nathaniel Rochester (IBM, 第一代通用计算机701主设计师) * 让机器能像人那样认知、思考和学习,即用计算机模拟人的智能。- 人工智能内涵与外延式定义,人工智能内涵式定义非常困难
人工智能外延式定义之一:人工智能是一门研究、开发用于模拟、延伸和扩展人类智能的理论、方法、技术及应用系统的技术科学“人工”:由人类开发研究出来的;由意识、思维、自我等等组成的复杂集合 —> “智能”
- 人工智能正在引发科学研究范式变革:数据驱动计算模式
人工智能正在引发科学研究范式变革:推动人类从继实验观测(从对自然现象的观测中总结规律)、理论型(计算+AI)为核心的数据洪流型(Data Torrent)第四范式发展1. 几千年前(科学实验)2. 数百年来 (模型归纳)3. 数十年来 (模拟仿真)4. 今天 (数据密集型)
- 人工智能内涵与外延式定义,人工智能内涵式定义非常困难
-
软件开发-用户故事
- 三个主要阶段
- 定义内容
- 两种类型
- Story cards: Agile开发相关
- 接受度测试Acceptance Tests
- 其他信息
- Scrum
- 原则Principles
- 概念
- 角色
- 回顾review
- 故事&故事思维
- 产品中的故事思维
- 构建故事
- User Story 如何写
- 传统需求分析:
- 互联网发展的现状:
- 什么是用户故事:
- 为什么要写用户故事:
- 用户故事的三个原则(3C);
- 用户故事的结构:
- 在做一个user story之前需要简单的对自己提问:
- 验收的条件则是:
- 验收标准的一个简单的例子:
- 户故事的负责人(3W):
- 用户故事的拆分:
- 用户故事的INVEST原则:
- Ending 完整的story生命周期
- 用户Story—基本要素
- 常见的Story模板
*软件开发(Software Development Processes):User Story Scrum **
三个主要阶段
- Concept 概念
- Implementation 实现
- Maintenance 维护
定义内容
- A set of tasks that need to be performed 需要完成的一系列任务
- Input & output from each task 每个任务的输入和输出
- Preconditions and Postconditions for each tasks 每个任务的前置条件和后置条件
- Sequence and flow of these tasks 任务的顺序和流程
两种类型
-
Plan Driven:
所有进程都事先计划好,用计划来评定进度
-
Agile:
计划是增量的(incremental),方便改变开发进程,以反映用户需求的改变
Story cards: Agile开发相关
- 我们想要一个轻量的方法来把我们的目标系统的功能块变成文档。
- 然后在sprint的不同迭代(iteration)中完成不同story的不同部分。
A defination of a piece of functionality from an end-user perspective. 也包含一些管理信息:priority,cost(时间相关的单位)
接受度测试Acceptance Tests
- Story cards的背面:可以在产品上做的测试,以检查这张卡要求的内容是否完成.(一张卡需要多个测试)。
其他信息
- 产品或者产品部件的名称/ID
- Story name
- 风险:任何可能影响story的完成或者提高成本的问题
- 笔记Notes:在完成一个story过程中的开发者工程笔记
Scrum
- 一个敏捷开发的框架(framework)。用于用一种增量的方式管理复杂的软件开发工作。
原则Principles
- 用户用product story/user story来定义他们在系统中想要的东西。
- User story不需要在一开始就很完整。
- 开发过程是迭代的(iterative),被分为很多个sprint(冲刺)
- 每个sprint都会处理user story的一个子集的问题。
- 一个story可能不能被一个sprint完成,则需要多个sprints
- 在每个sprint的结尾,整个队伍要整个sprint的进度
- 整个队伍要时常回顾进度(比如每天),每个小会议都成为一个Scrum
- 各个时间段都有可能加入新的story
Sprint Planning –> Implementation(daily scrum) –> Sprint Review –> Sprint Retrospect(回顾) –> …(loop)—> Deployment
概念
- Project back-log:整个project所有user story的完整列表
- Sprint:一个有固定的时间框架的开发周期(2-4周)
- Sprint Back-log: 分配给一个Sprint的user stories
- Sprint Team:在一个sprint中处理一组user stories的一个开发小组
- Scrum:Sprint小组中频繁举行的会议。用于跟进进度。已经完成了什么?接下来做什么?有哪些阻碍?
- Sprint Review:在Sprint的结尾,回顾已完成的哪些story
- Sprint Retrospective:在Sprint的结尾,总结一下遇到过哪些问题
角色
- Product Owner
- 负责维护Project Backlog
- 负责写User stories
- 设置story的优先级,将story分配给各个sprint
- Scrum Master
- 组织、主持Scrum会议
- 促进队伍中问题的解决
回顾review
每个Sprint结束后都要进行回顾,评估工作的完成情况。
-
Sprint review
- Product Owner列出已经完成的工作
- 团队讨论:是否成功?有什么问题?问题是如何解决的?
- 展示现有的产品
- Product Owner对backlog进行总结
- 分配下一个Sprint的Stories
-
Sprint Retrospective
- 是一种比review更高等级的总结评定!关键在于寻找可以提升开发效率的战略性改变。例如:重新分配团队中的角色,改变优先级,增加和移除stories,等等
故事&故事思维
故事是一种信息的传递方式,在形式上强调生动性、连贯性,真实性(至少听起来真实),能引起情感共鸣;内容上故事本身具有其主基调,每个情节之间能够环环相扣,具备吸引人的关键词等。故事,由于其本身固有得特点,在信息传递过程中有交互、有场景、有情节,容易引起故事听众的共鸣,可以让人更好地记忆内容,也使得内容可以更快更广泛地传播。故事思维,是运用故事的元素进行思考和设计,以求解决某种问题,达到特定处事效果的思维。
产品中的故事思维
什么是产品中的故事思维呢?
就是将故事思维运用在产品的需求收集、创新、设计、改进,帮助我们在做产品的过程中看清用户使用产品的现状是什么,了解用户在使用现有产品遇到什么困难,解决用户现有场景不能被满足的需求我们的解决方案是什么,以及描述产品以后会是什么样子,能解决用户什么问题,为用户带来什么价值。
构建故事
构建故事,我们需要有故事应该具备的基本要素。
- 可信的环境(时间、地点)
- 可信的角色(谁、为什么)
- 流畅的情节(是什么、怎么样)
环境、角色、情节是构建一个故事的基本要素,前面加上定语是因为一个成型的故事必须是生动、连贯以及可信的。虽然大多数故事都是经过了一些渲染和包装,但是一个故事需要打动别人,必须具备真实性,即使不是真实发生的,但至少听起来真实。
User Story 如何写
传统需求分析:
- 时间:需求分析两个月,开发三个月
- 出现的问题:有些功能没有人使用,有些功能做错了/不要用,频繁变更,走向更大批量
- 原因:没有抓住用户/客户核心需求,优先级不正确,大批量
互联网发展的现状:
- 不确定性增大
- 市场变化快
什么是用户故事:
- 用户故事是简要的意向性描述,它描述系统需要为用户做的事情以及对用户的价值
- 迭代式开发的工具
- 代表了可开发的一个工作单元
- 帮助跟踪一个功能的生命周期
- 引起对话的载体/占位符
为什么要写用户故事:
-
- 更早的提交产品来满足需求
-
- 消除软件开发过程中的浪费
-
- 团队更关注用户需求价值
-
- 加强团队的沟通,减少信息传递的失真
用户故事的三个原则(3C);
- card:写在一个卡片上,用这个卡片与开发团队进行对话
- 务价值的reminder
- 做计划和沟通的token
- 卡片的两个部分:作为<用户角色>想要<完成活动>实现<价值>;验收标准**
**
- conversation:用于在计划或估值时引发关于故事细节的对话
- 用于在计划或估值时引发关于用户细节的对话
- confirmation:将细节以验收测试的方式来确认故事的完整性和正确性
用户故事的结构:
>> TitleDescription作为 (As a)“某类利益相关者”我想要(I want)“目标系统提供的行为或功能”以便(So that)”实现某种业务价值或目标”Narrative – 业务背景/工作流程Acceptance Criteria – 验收标准Mock Up – 原型图其他有帮助的内容在做一个user story之前需要简单的对自己提问:
- 如果没有这个故事
- 谁会不高兴
- 谁的利益会受损
- 什么样的利益会受损
- 如果存在其它方法
- 为什么不用其他方法
- 能不能够只做一部分
- 能的话是哪一部分,为什么
验收的条件则是:
- Gievn (在什么样的情景或条件下)
- When(做了什么操作,采取了什么行为)
- Then(得到了什么结果)
验收标准的一个简单的例子:
- Gievn:当邮件的发送者在邮件书面写完了邮件主体(没有加粗)
- When:选中其中的几个文字,点击加粗按钮
- Then:选中的文字粗体显示
户故事的负责人(3W):
- who谁写: 产品负责人/PO 客户/用户
- Where 在哪里些 故事卡片 工具
- When 得到需求后 需求探索的过程中
用户故事的拆分:
- 主题 Themes
- 特性 Feature
- 需求集 Epic
- 用户故事 User Story
用户故事的INVEST原则:
I:independent 独立性,各自完整,独立于其他用户故事
N:Negotiable 可协商,总是可以被替换和重写,直到成为迭代的一个部分
V:Valuable 有价值,一定要能对最终用户或商业有价值
E:Estimable 可估值,参考其他故事,功能点的大小可以被评估
Scalable:大小合适,小于一个迭代
Testable:可测试,提供可被验证的必要信息,证明它有用
Ending 完整的story生命周期
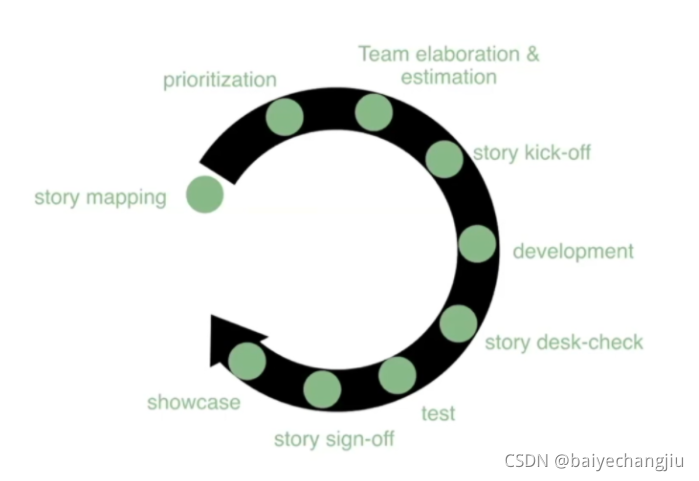
用户Story—基本要素
写用户Story的时候我们需要围绕三个基本要素来写。用户(角色)、需求(目的)、原因(好处)三点。通过一定的需要修饰就组成了我们常见的Story语句。
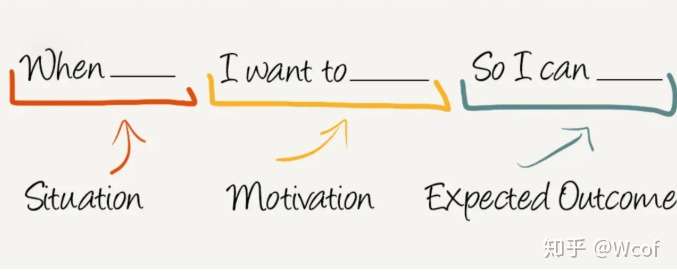
常见的Story模板
- 一、我是(角色),我希望(功能),这样(好处)。
- 二、作为(角色),我想要(商业价值),以便(原因)。
- 三、作为(角色),我想(目标),以便(某种原因)。
在写Story的时候我们需要尽可能的保持刚刚好的详细,让用户Story有”笔直性”。避免增加过多的细节要求,让Story变得复杂。
-
PaddleServing图像语义分割部署实践
PaddleServing图像语义分割部署实践
一、任务概述
本教程基于PaddleServing实现图像语义分割模型部署。首先我们会按照官方示例将部署流程跑一边,然后我们逐步调整代码和配置,基于更通用的PipeLine模式全流程实现抠图功能部署。
二、官方示例部署
2.1 安装PaddleServing
从官网下载最新稳定离线版whl文件进行安装,各组件安装命令如下:
# 安装客户端: pip install paddle-serving-client # 安装服务器端(CPU或者GPU版二选一): 安装CPU服务端:pip install paddle-serving-server 安装GPU服务端:pip install paddle-serving-server-gpu 安装工具组件:pip install paddle-serving-app在安装时为了加速可以添加百度镜像源参数:
-i https://mirror.baidu.com/pypi/simple2.2 导出静态图模型
一般来说我们使用PaddlePaddle动态图训练出来的模型如果直接部署,其推理效率是比较低的。为了能够实现高效、稳定部署,我们需要将训练好的模型转换为静态图模型。
导出示例请参考官网说明。
这里我们使用官网示例给出的转换好的模型进行操作。
下载静态图模型:
wget https://paddleseg.bj.bcebos.com/dygraph/demo/bisenet_demo_model.tar.gz tar zxvf bisenet_demo_model.tar.gz解压后看到模型文件夹中内容如下所示: 然后我们准备一张用于测试的街景图像:
 到这里,需要的部署数据都准备好了。
到这里,需要的部署数据都准备好了。2.3 转换为serving模型
为了能够使用Paddle Serving工具实现AI服务器云部署,我们需要前面准备好的静态图模型转换为Paddle Serving可以使用的部署模型。 我们将使用
paddle_serving_client.convert工具进行转换,具体命令如下:python -m paddle_serving_client.convert \ --dirname ./bisenetv2_demo_model \ --model_filename model.pdmodel \ --params_filename model.pdiparams执行完成后,当前目录下的serving_server文件夹保存服务端模型和配置,serving_client文件夹保存客户端模型和配置,如下图所示:

2.4 启动服务
按照官方示例,我们使用paddle_serving_server.serve的RPC服务模式,详细信息请参考文档。(需要注意的是,这种模式本质上是C/S架构,优势是响应快,缺点是在客户端需要安装相应的库并需要编写预处理代码)
我们在服务器端使用
27008端口。python3 -m paddle_serving_server.serve \ --model serving_server \ --thread 10 \ --port 27008 \ --ir_optim启动后如果我们机器上没有安装对应版本的tensorrt,那么启动会出现如下错误: error while loading shared libraries: libnvinfer.so.6: cannot open shared object file: No such file or directory 我们需要下载tensorrt库并将其添加到自己的环境变量去(注意tensortrt版本要与我们安装的paddle-serving-server-gpu版本一致)。相关解决方案请参考博客。安装完成后需要导入环境变量:
打开并编辑bashrc文件:
vim ~/.bashrc在文件最后添加:export LD_LIBRARY_PATH=/home/suser/copy/TensorRT-6.0.1.8/lib:$LD_LIBRARY_PATH保存修改后把相关文件进行拷贝:
sudo cp TensorRT-6.0.1.8/targets/x86_64-linux-gnu/lib/libnvinfer.so.6 /usr/lib/最后使用下面的命令使其生效:
source ~/.bashrc重新启动服务端就可以正常跑起来了。2.5 客户端请求
客户端采用python脚本进行访问请求。 完整请求代码如下:
import os import numpy as np import argparse from PIL import Image as PILImage from paddle_serving_client import Client from paddle_serving_app.reader import Sequential, File2Image, Resize, CenterCrop from paddle_serving_app.reader import RGB2BGR, Transpose, Div, Normalize def get_color_map_list(num_classes, custom_color=None): num_classes += 1 color_map = num_classes * [0, 0, 0] for i in range(0, num_classes): j = 0 lab = i while lab: color_map[i * 3] |= (((lab >> 0) & 1) << (7 - j)) color_map[i * 3 + 1] |= (((lab >> 1) & 1) << (7 - j)) color_map[i * 3 + 2] |= (((lab >> 2) & 1) << (7 - j)) j += 1 lab >>= 3 color_map = color_map[3:] if custom_color: color_map[:len(custom_color)] = custom_color return color_map def get_pseudo_color_map(pred, color_map=None): pred_mask = PILImage.fromarray(pred.astype(np.uint8), mode='P') if color_map is None: color_map = get_color_map_list(256) pred_mask.putpalette(color_map) return pred_mask def parse_args(): parser = argparse.ArgumentParser(description='') parser.add_argument( "--serving_client_path", help="The path of serving_client file.", type=str, required=True) parser.add_argument( "--serving_ip_port", help="The serving ip.", type=str, default="127.0.0.1:9292", required=True) parser.add_argument( "--image_path", help="The image path.", type=str, required=True) return parser.parse_args() def run(args): client = Client() client.load_client_config( os.path.join(args.serving_client_path, "serving_client_conf.prototxt")) client.connect([args.serving_ip_port]) seq = Sequential([ File2Image(), RGB2BGR(), Div(255), Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5], False), Transpose((2, 0, 1)) ]) img = seq(args.image_path) fetch_map = client.predict( feed={"x": img}, fetch=["save_infer_model/scale_0.tmp_1"]) result = fetch_map["save_infer_model/scale_0.tmp_1"] color_img = get_pseudo_color_map(result[0]) color_img.save("./result.png") print("The segmentation image is saved in ./result.png") if name == 'main': args = parse_args() run(args)然后使用下面的命令启动:
python test.py \ --serving_client_path serving_client \ --serving_ip_port 127.0.0.1:27008 \ --image_path cityscapes_demo.png运行后可能会出现下面的错误:
libcrypto.so.10: cannot open shared object file: No such file or directory解决方案如下:
wget https://paddle-serving.bj.bcebos.com/others/centos_ssl.tar tar xf centos_ssl.tar rm -rf centos_ssl.tar sudo mv libcrypto.so.1.0.2k /usr/lib/libcrypto.so.1.0.2k sudo mv libssl.so.1.0.2k /usr/lib/libssl.so.1.0.2k sudo ln -sf /usr/lib/libcrypto.so.1.0.2k /usr/lib/libcrypto.so.10 sudo ln -sf /usr/lib/libssl.so.1.0.2k /usr/lib/libssl.so.10 sudo ln -sf /usr/lib/libcrypto.so.10 /usr/lib/libcrypto.so sudo ln -sf /usr/lib/libssl.so.10 /usr/lib/libssl.so修改后重新执行客户端请求代码,结果如下图所示:
I0423 10:45:54.155158 20937 naming_service_thread.cpp:202] brpc::policy::ListNamingService("127.0.0.1:27008"): added 1 I0423 10:46:01.689276 20937 general_model.cpp:490] [client]logid=0,client_cost=7292.98ms,server_cost=6954.06ms. The segmentation image is saved in ./result.png执行完成后,分割的图片保存在当前目录的
result.png。 分割结果如下图所示:
想要彻底停止服务可以使用下面的命令:
ps -ef | grep serving | awk '{print $2}' | xargs kill -9 ps -ef | grep web_service | awk '{print $2}' | xargs kill -9从整个执行上来分析,这种基于RPC的方式有个明显的缺点,就是需要客户端来实现所有的预处理和后处理操作。这对于跨语言的应用任务来说是比较麻烦的,例如我们如果采用java作为前台语言,那么就只能使用java来执行图像相关预处理和后处理。为了解决这个问题,
paddle serving提供了java版的客户端,其本质是一个封装好的基于java的图像预处理工具。前端程序员还是需要手工编写客户端代码,协调合作时比较麻烦。下面我们将使用另一种
pipeline的方法,所有的预处理和后处理也一起交给服务端去做,这样就彻底跟前端功能剥离开来,前后端之间通过http接口进行通讯。这种方式相对于RPC模式来说速度会慢一些,但是很显然,其通用性更好。下面我们就使用一个更加具体的抠图任务来实现整个的PipeLine部署。
三、基于PipeLine的抠图功能部署
3.1 基于深度学习的抠图功能测试
3.1.1 算法库下载
首先从github官网下载最新的paddleseg套件,也可以从我的gitee镜像上下载(速度会快一些):
git clone https://gitee.com/binghai228/PaddleSeg.git cd PaddleSeg pip install -r requirements.txt -i https://mirror.baidu.com/pypi/simple python setup.py install注意如果本地安装失败,也可以使用在线安装方式:
cd PaddleSeg pip install -r requirements.txt -i https://mirror.baidu.com/pypi/simple pip install paddleseg==2.5.0 cd到Matting文件夹中: cd PaddleSeg/Matting这个文件夹下面就是
PaddleSeg官方在维护的抠图算法套件。 3.1.2 抠图算法说明 Matting(精细化分割/影像去背/抠图)是指借由计算前景的颜色和透明度,将前景从影像中撷取出来的技术,可用于替换背景、影像合成、视觉特效,在电影工业中被广泛地使用。影像中的每个像素会有代表其前景透明度的值,称作阿法值(Alpha),一张影像中所有阿法值的集合称作阿法遮罩(Alpha Matte),将影像被遮罩所涵盖的部分取出即可完成前景的分离。相关功能实现效果如下:

PaddleSeg套件提供多种场景人像抠图模型, 可根据实际情况选择相应模型。这里我们选择PP-Matting-512模型进行部署应用。读者也可以参照官网教程自行训练模型,然后转为静态图模型使用。本教程更偏重算法部署,对于算法原理和训练本教程不再深入阐述,对深度学习抠图有兴趣的读者可以参考我的另一篇博客了解相关算法原理。
3.1.3 抠图算法测试
首先下载训练好的模型。如下图所示:

模型下载后解压放置在Matting/data文件夹下。 然后我们下载PPM-100数据集用于后续测试。下载下来后解压放置在Matting/data目录下。
最终我们可以使用下面的脚本命令进行测试:
python deploy/python/infer.py \ --config data/pp-matting-hrnet_w18-human_512/deploy.yaml \ --image_path data/PPM-100/val/fg/ \ --save_dir output/results推理完成后在output/results目录下保存了抠图后的测试图像结果。 部分效果如下:


从效果上分析,整体抠图性能还是比较好的。 当然,对于一些复杂的照片抠图效果还是有待再提高的,例如下面的示例:


3.2 基于PipeLine的Serving部署
3.2.1 转换为serving部署模型
使用
paddle_serving_client.convert工具进行转换,具体命令如下:python -m paddle_serving_client.convert \ --dirname ./data/pp-matting-hrnet_w18-human_512 \ --model_filename model.pdmodel \ --params_filename model.pdiparams执行完成后,当前目录下的serving_server文件夹保存服务端模型和配置,serving_client文件夹保存客户端模型和配置,如下图所示: 我们打开serving_server_conf.prototxt文件,其内容如下所示:
feed_var { name: "img" alias_name: "img" is_lod_tensor: false feed_type: 1 shape: 3 } fetch_var { name: "tmp_75" alias_name: "tmp_75" is_lod_tensor: false fetch_type: 1 shape: 1 }根据这个文件,我们在写部署代码的时候需要注意对应的输入、输出变量名称,这里输入变量名为img,输出变量名为tmp_75。 3.2.2 设置config.yml部署配置文件
在当前目录下新建config.yml文件,内容如下:
dag: #op资源类型, True, 为线程模型;False,为进程模型 is_thread_op: false #使用性能分析, True,生成Timeline性能数据,对性能有一定影响;False为不使用 use_profile: false # tracer: # interval_s: 30 #http端口, rpc_port和http_port不允许同时为空。当rpc_port可用且http_port为空时,不自动生成http_port http_port: 27008 #worker_num: 2 #最大并发数。当build_dag_each_worker=True时, 框架会创建worker_num个进程,每个进程内构建grpcSever和DAG #build_dag_each_worker, False,框架在进程内创建一条DAG;True,框架会每个进程内创建多个独立的DAG build_dag_each_worker: false #rpc端口, rpc_port和http_port不允许同时为空。当rpc_port为空且http_port不为空时,会自动将rpc_port设置为http_port+1 #rpc_port: 27009 op: matting: #并发数,is_thread_op=True时,为线程并发;否则为进程并发 concurrency: 4 local_service_conf: #client类型,包括brpc, grpc和local_predictor.local_predictor不启动Serving服务,进程内预测 client_type: local_predictor # device_type, 0=cpu, 1=gpu, 2=tensorRT, 3=arm cpu, 4=kunlun xpu device_type: 1 #计算硬件ID,当devices为""或不写时为CPU预测;当devices为"0", "0,1,2"时为GPU预测,表示使用的GPU卡 devices: '0,1,2,3' #Fetch结果列表,model中fetch_var的alias_name为准, 如果没有设置则全部返回 fetch_list: - tmp_75 #模型路径 model_config: serving_server如果要部署自己的模型请根据注释结合自己需要部署的模型参数对照着进行修改。
3.2.3 编写服务端脚本文件
新建
web_service.py文件,内容如下:import numpy as np import cv2 from paddle_serving_app.reader import * import base64 from paddle_serving_server.web_service import WebService, Op class MattingOp(Op): ''' 定义抠图算子 ''' def init_op(self): ''' 初始化 ''' self.img_preprocess = Sequential([ #BGR2RGB(), Div(255.0), #Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225], False), Resize(512), Transpose((2, 0, 1)) ]) self.ref_size = 512 self.img_width = self.ref_size self.img_height = self.ref_size def preprocess(self, input_dicts, data_id, log_id): ''' 预处理 ''' (_, input_dict), = input_dicts.items() imgs = [] for key in input_dict.keys(): # 解码图像 data = base64.b64decode(input_dict[key].encode('utf8')) data = np.fromstring(data, np.uint8) im = cv2.imdecode(data, cv2.IMREAD_COLOR) self.im = im self.img_height,self.img_width,_ = im.shape # 短边对齐512,长边设置为32整数倍(根据算法模型要求) im_h, im_w, _ = im.shape if im_w >= im_h: im_rh = self.ref_size im_rw = int(im_w *1.0 / im_h * self.ref_size) elif im_w < im_h: im_rw = self.ref_size im_rh = int(im_h *1.0 / im_w * self.ref_size) im_rw = im_rw - im_rw % 32 im_rh = im_rh - im_rh % 32 im = cv2.resize(im,(im_rw,im_rh)) # cv2转tensor im = self.img_preprocess(im) imgs.append({ "img": im[np.newaxis, :], # "im_shape":np.array(list(im.shape[1:])).reshape(-1)[np.newaxis, :], # "scale_factor": np.array([1.0, 1.0]).reshape(-1)[np.newaxis, :], }) # 准备输入数据 feed_dict = { "img": np.concatenate( [x["img"] for x in imgs], axis=0), # "im_shape": np.concatenate( # [x["im_shape"] for x in imgs], axis=0), # "scale_factor": np.concatenate( # [x["scale_factor"] for x in imgs], axis=0) } #for key in feed_dict.keys(): # print(key, feed_dict[key].shape) return feed_dict, False, None, "" def postprocess(self, input_dicts, fetch_dict, data_id, log_id): ''' 后处理 ''' # 取出掩码图 alpha = fetch_dict["tmp_75"] alpha = alpha.squeeze(0).squeeze(0) alpha = (alpha * 255).astype('uint8') alpha = cv2.resize( alpha, (self.img_width, self.img_height), interpolation=cv2.INTER_NEAREST) alpha = alpha[:, :, np.newaxis] clip = np.concatenate([self.im, alpha], axis=-1) print(clip.shape) _, buffer_img = cv2.imencode('.png', clip) # 在内存中编码为png格式 img64 = base64.b64encode(buffer_img) img64 = str(img64, encoding='utf-8') # bytes转换为str类型 #封装成字典返回 res_dict = { "alpha":img64 } return res_dict, None, "" class MattingService(WebService): ''' 定义服务 ''' def get_pipeline_response(self, read_op): matting_op = MattingOp(name="matting", input_ops=[read_op]) return matting_op # 创建服务 matting_service = MattingService(name="matting") # 加载配置文件 matting_service.prepare_pipeline_config("config.yml") # 启动服务 matting_service.run_service()上述代码做了注释,读者可以自行阅读分析。
最后使用下面的命令启动服务:
python web_service.py3.2.4 客户端调用
这里需要注意,由于我们采用了Pipeline模式,所有的图像预处理和后处理操作都放在了服务端,因此,客户端不需要加载额外的库,也不需要进行相关图像预处理代码编写。因此,我们可以采用任何客户端方式(浏览器、脚本、移动端等),只需要按照http restful协议传送相关json数据即可。
本文为了简单,采用python脚本来作为客户端(也可以仿照这个脚本使用postman进行测试)。新建脚本文件
pipeline_http_client.py,具体代码如下:import numpy as np import requests import json import cv2 import base64 def cv2_to_base64(image): return base64.b64encode(image).decode('utf8') # 定义http接口 url = "http://127.0.0.1:27008/matting/prediction" # 打开待预测的图像文件 with open('./data/PPM-100/val/fg/1.jpg', 'rb') as file: image_data1 = file.read() # 采用base64编码图像文件 image = cv2_to_base64(image_data1) # 按照特定格式封装成字典 data = {"key": ["image"], "value": [image]} # 发送请求 r = requests.post(url=url, data=json.dumps(data)) # 解析返回值 r = r.json() # 解码返回的图像数据 img = r"value" img = bytes(img, encoding='utf-8') # str转bytes img = base64.b64decode(img) # base64解码 img = np.asarray(bytearray(img), dtype="uint8") img = cv2.imdecode(img, cv2.IMREAD_UNCHANGED) # 保存图像到本地 if img is None: print('call error') else: cv2.imwrite('result.png',img) print('完成')执行预测:
python3 pipeline_http_client.py四、小结
本教程以PaddleServing部署为目标,以语义分割(抠图)案例贯穿整个部署环节,最终成功实现服务器线上部署和调用。通过本教程的学习,可以快速将训练好的深度学习模型进行上线,同时具备良好的稳定性。
-
ZLMediaKit 流媒体服务搭建
流媒体服务学习笔记