欢迎来到@ZhangHaipeng主页!
让知识成为信仰,让优秀成为习惯-
Machine Learning Online Processing
2021-05-202. 请简要说说一个完整机器学习项目的流程
1 抽象成数学问题
明确问题是进行机器学习的第一步。机器学习的训练过程通常都是一件非常耗时的事情,胡乱尝试时间成本是非常高的。 这里的抽象成数学问题,指的我们明确我们可以获得什么样的数据,目标是一个分类还是回归或者是聚类的问题,如果都不是的话,如果划归为其中的某类问题。
2 获取数据
数据决定了机器学习结果的上限,而算法只是尽可能逼近这个上限。 数据要有代表性,否则必然会过拟合。 而且对于分类问题,数据偏斜不能过于严重,不同类别的数据数量不要有数个数量级的差距。 而且还要对数据的量级有一个评估,多少个样本,多少个特征,可以估算出其对内存的消耗程度,判断训练过程中内存是否能够放得下。如果放不下就得考虑改进算法或者使用一些降维的技巧了。如果数据量实在太大,那就要考虑分布式了。
3 特征预处理与特征选择
良好的数据要能够提取出良好的特征才能真正发挥效力。 特征预处理、数据清洗是很关键的步骤,往往能够使得算法的效果和性能得到显著提高。归一化、离散化、因子化、缺失值处理、去除共线性等,数据挖掘过程中很多时间就花在它们上面。这些工作简单可复制,收益稳定可预期,是机器学习的基础必备步骤。 筛选出显著特征、摒弃非显著特征,需要机器学习工程师反复理解业务。这对很多结果有决定性的影响。特征选择好了,非常简单的算法也能得出良好、稳定的结果。这需要运用特征有效性分析的相关技术,如相关系数、卡方检验、平均互信息、条件熵、后验概率、逻辑回归权重等方法。
4 训练模型与调优
直到这一步才用到我们上面说的算法进行训练。现在很多算法都能够封装成黑盒供人使用。但是真正考验水平的是调整这些算法的(超)参数,使得结果变得更加优良。这需要我们对算法的原理有深入的理解。理解越深入,就越能发现问题的症结,提出良好的调优方案。
5 模型诊断
如何确定模型调优的方向与思路呢?这就需要对模型进行诊断的技术。 过拟合、欠拟合 判断是模型诊断中至关重要的一步。常见的方法如交叉验证,绘制学习曲线等。过拟合的基本调优思路是增加数据量,降低模型复杂度。欠拟合的基本调优思路是提高特征数量和质量,增加模型复杂度。 误差分析 也是机器学习至关重要的步骤。通过观察误差样本,全面分析误差产生误差的原因:是参数的问题还是算法选择的问题,是特征的问题还是数据本身的问题…… 诊断后的模型需要进行调优,调优后的新模型需要重新进行诊断,这是一个反复迭代不断逼近的过程,需要不断地尝试, 进而达到最优状态。
6 模型融合
一般来说,模型融合后都能使得效果有一定提升。而且效果很好。 工程上,主要提升算法准确度的方法是分别在模型的前端(特征清洗和预处理,不同的采样模式)与后端(模型融合)上下功夫。因为他们比较标准可复制,效果比较稳定。而直接调参的工作不会很多,毕竟大量数据训练起来太慢了,而且效果难以保证。
7 上线运行
这一部分内容主要跟工程实现的相关性比较大。工程上是结果导向,模型在线上运行的效果直接决定模型的成败。 不单纯包括其准确程度、误差等情况,还包括其运行的速度(时间复杂度)、资源消耗程度(空间复杂度)、稳定性是否可接受。 这些工作流程主要是工程实践上总结出的一些经验。并不是每个项目都包含完整的一个流程。这里的部分只是一个指导性的说明,只有大家自己多实践,多积累项目经验,才会有自己更深刻的认识。
-
Python Coding Style
2019-03-06如何编写高质量的Pythonic风格代码?
我知道有些新人肯定不了解Pythonic是什么,也许在某些论坛看到过这个词语。其实,它的意思很简单。这是Python的开发者用来表示代码风格的名词。它是在Python开发过程中指定的一种指南,一种习惯。宗旨是 直观、简洁、易读
1、不用害怕长变量名 长一点的变量名,有时候是为了让程序更容易理解和阅读。并且,有的编辑器已经支持自动提示,所以不用太担心敲键盘太多的烦恼。 比如: user_info 就是比 ui 的可读性高很多: user_info = {‘name’:’xiyouMc’,’age’:’保密’,’address’:’Hangzhou’} 2、避免使用容易混淆的名称 尽量不要使用 内建 的函数名来表示其他含义的名称。比如 list、dict等。不要使用 o(字符O的小写,很容易被当做数字0),1(字母 L 的小写,也容易和数字 1 混淆) 其次,变量名最好和你要解决的问题联系起来。 3、尽量不要使用大小写来区分不同的对象 比如 b是一个树脂类型的变量,但 A 是 String 类型,虽然在编码过程中容易区分这两者的含义,但是没啥卵用,它并不会给其他阅读代码的人带来福利。反而,带来的呕吐的感觉。 4、其次,最重要的一点是,多看源码,学习别人的风格 Github 上有数不胜数的优秀代码,比如web框架里面有名的Flask、Requests,还有爬虫界的Scrapy,这些都是经典中的经典,并且都是比较好的理解pythonic代码风格精髓的例子。 5、最后,你实在是懒得不想关注这些,只想写代码,那么。。。 我推荐一个神器,在你写完代码之后,执行这个神器就可以看到检测代码风格后的结果。 PEP8,全称,”Python Enhancement Proposal #8”,它列举除了很多对代码的布局、注释、命名的要求。 pip install -U pep8 #来安装 pep8 然后用它来检测代码: ➜ /Users/xiyoumc >pep8 –first pornHubSpider.py pornHubSpider.py:1:1: E265 block comment should start with ‘# ‘ pornHubSpider.py:19:43: E124 closing bracket does not match visual indentation pornHubSpider.py:22:16: E251 unexpected spaces around keyword / parameter equals pornHubSpider.py:53:5: E301 expected 1 blank line, found 0 pornHubSpider.py:71:22: W503 line break before binary operator
同时,如果对pep8感兴趣的话,可以留言,我可以开个系列来讲解 PEP8里面的变量、函数、类、木块和包,这样就会更加容易的理解Pythonic风格。 最后,如若我写的对大家有点帮助,那么关注公众号 DeveloperPython,你将会收到关于Python技术第一时间的推送。
编写Pythonic代码 避免劣化代码
避免只用大小写来区分不同的对象; 避免使用容易引起混淆的名称,变量名应与所解决的问题域一致; 不要害怕过长的变量名;代码中添加适当注释
行注释仅注释复杂的操作、算法,难理解的技巧,或不够一目了然的代码; 注释和代码要隔开一定的距离,无论是行注释还是块注释; 给外部可访问的函数和方法(无论是否简单)添加文档注释,注释要清楚地描述方法的功能,并对参数,返回值,以及可能发生的异常进行说明,使得外部调用的人仅看docstring就能正确使用; 推荐在文件头中包含copyright申明,模块描述等; 注释应该是用来解释代码的功能,原因,及想法的,不该对代码本身进行解释; 对不再需要的代码应该将其删除,而不是将其注释掉;适当添加空行使代码布局更为优雅、合理
在一组代码表达完一个完整的思路之后,应该用空白行进行间隔,推荐在函数定义或者类定义之间空两行,在类定义与第一个方法之间,或需要进行语义分隔的地方空一行,空行是在不隔断代码之间的内在联系的基础上插入的; 尽量保证上下文语义的易理解性,一般是调用者在上,被调用者在下; 避免过长的代码行,每行最好不要超过80字符; 不要为了保持水平对齐而使用多余的空格;编写函数的几个原则
函数设计要尽量短小,嵌套层次不宜过深; 函数申明应做到合理、简单、易于使用,函数名应能正确反映函数大体功能,参数设计应简洁明了,参数个数不宜过多; 函数参数设计应考虑向下兼容; 一个函数只做一件事,尽量保证函数语句粒度的一致性;将常量集中到一个文件
Python没有提供定义常量的直接方式,一般有两种方法来使用常量;
通过命名风格来提醒使用者该变量代表的意义为常量,如常量名所有字母大写,用下划线连接各个单词,如MAX_NUMBER,TOTLE等; 通过自定义的类实现常量功能,常量要求符合两点,一是命名必须全部为大写字母,二是值一旦绑定便不可再修改; ``` class _const: class ConstError(TypeError): pass class ConstCaseError(ConstError): pass def __setattr__(self, name, value): if name in self.__dict__: rasie self.ConstError, "Can't change const.%s" % name if not name.isupper(): raise self.ConstCaseError, "const name '%s' is not all uppercase" % name self.__dict__[name] = valueimport sys sys.modules[name] = _const()
# ============================================================================== 基本遵从 PEP 准则 …… 但是,命名和单行长度更灵活。 PEP8 涵盖了诸如空格、函数/类/方法之间的换行、import、对已弃用功能的警告之类的寻常东西,大都不错。 应用这些准则的最佳工具是 flake8,还可以用来发现一些愚蠢的语法错误。 PEP8 原本只是一组指导原则,不必严格甚至虔诚地信奉。一定记得阅读 PEP8 「愚蠢的一致性就是小人物的小妖精」一节。若要进一步了解,可以听一下 Raymond Hettinger 的精彩演讲,「超越 PEP8」。 唯一引起过多争议的准则事关单行长度和命名。要调整起来也不难。 灵活的单行长度 若是厌烦 flake8 死板的单行长度不得超过 79 个字符的限制,完全可以忽略或修改这一准则。这仍然不失为一条不错的经验法则,就像英语中句子不能超过 50 个单词,段落不能超过 10 个句子之类的规则一样。这是 flake8 配置文件 的链接,可以看到 max-line-length配置选项。值得注意的是,可以给要忽略 flake8 检查的那一行加上 # noqa 注释,但是请勿滥用。 尽管如此,超过九成的代码行都不应该超过 79 个字符,原因很简单,「扁平胜于嵌套」。如果函数每一行都超出了 79 个字符,肯定有别的东西出错了,这时要看看代码而不是 flake8 配置。 一致的命名 关于命名,遵循几条简单的准则就可以避免众多足以影响整个小组的麻烦。 推荐的命名规则 下面这些准则大多改编自 Pacoo 小组。 类名:驼峰式 和首字母缩略词:HTTPWriter 优于 HttpWriter。 变量名:lower_with_underscores。 方法名和函数名:lower_with_underscores。 模块名:lower_with_underscores.py。(但是不带下划线的名字更好!) 常量名:UPPER_WITH_UNDERSCORES。 预编译的正则表达式:name_re。 通常都应该遵循这些准则,除非要参照其他工具的命名规范,比如数据库 schema 或者消息格式。 还可以用 驼峰式 给类似类却不是类的东西命名。使用 驼峰式 的主要好处在于让人们以「全局名词」来关注某个东西,而不是看作局部标记或动词。值得注意的是,Python 给 True,False 和 None 这些根本不是类的东西命名也是用 驼峰式。 不要用前缀后缀 …… 比如 _prefix 或 suffix_ 。函数和方法名可以用 _prefix 标记来暗示其是「私有的」,但是最好只在编写预期会广泛使用的 API 以及用 _prefix 标记来隐藏信息的时候谨慎使用。 PEP8 建议使用结尾的下划线来避免与内置关键字重名,比如: ```python sum_ sum(some_long_list) print(sum_)临时这样用也可以,不过最好还是选一个别的名字。
用 mangled 这种双下划线前缀给类/实例/方法命名的情况非常少,这实际上涉及特殊的名字修饰,非常罕见。不要起 __dunder 这种格式的名字,除非要实现 Python 标准协议,比如 len;这是为 Python 内部协议保留的命名空间,不应该在其中增加自定义的东西。 不要用单字符名字
(不过)一些常见的单字符名字可以接受。
在 lambda 表达式中,单参数函数可以命名为 x 。比如:
encode = lambda x: x.encode("utf-8", "ignore")使用 self 及类似的惯例
应该:
永远将方法的第一个变量命名为 self 永远将 @classmethod 的第一个参数命名为 cls 永远在变量参数列表中使用 *args 和 **kwargs不要在这些地方吹毛求疵
不遵循如下准则没有什么好处,干脆照它说的做。 永远继承自 object 并使用新式类
# bad class JSONWriter: pass # good class JSONWriter(object): pass对于 Python 2 来说遵循这条准则很重要。不过由于 Python 3 所有的类都隐式继承自 object,这条准则就没有必要了。 不要在类中重复使用实例标记
# bad class JSONWriter(object): handler = None def __init__(self, handler): self.handler = handler # good class JSONWriter(object): def __init__(self, handler): self.handler = handler用 isinstance(obj, cls), 不要用 type(obj) == cls
因为 isinstance 涵盖更多情形,包括子类和抽象基类。同时,不要过多使用 isinstance,因为通常应该使用鸭子类型! 用 with 处理文件和锁
with 语句能够巧妙地关闭文件并释放锁,哪怕是在触发异常的情况下。所以:
# bad somefile = open("somefile.txt", "w") somefile.write("sometext") return # good with open("somefile.txt", "w") as somefile: somefile.write("sometext") return和 None 相比较要用 is
None 值是一个单例,但是检查 None 的时候,实际上很少真的要在 左值上调用 eq。所以:
# bad if item == None: continue # good if item is None: continue好的写法不仅执行更快,而且更准确。使用 == 并不会更简洁,所以请记住本规则! 不要修改 sys.path
通过 sys.path.insert(0, “../”) 等操作来控制 Python 的导入方法或许让人心动,但是要坚决避免这样做。
Python 有一套有几分复杂,却易于理解的模块路径解决方法。可以通过 PYTHONPATH 或诸如 setup.py develop 的技巧来调整 Python 导入模块的方法。还可以用 -m 运行 Python 得到需要的效果,比如使用 python -m mypkg.mymodule 而不是 python mypkg/mymodule.py。代码能否正常运行不应依赖于当前执行 Python 的工作路径。David Beazley 用 PDF 幻灯片再一次扭转了大家的看法,值得一读,“Modules and Packages: Live and Let Die!”。 尽量不要自定义异常类型
…… 如果一定要,也不要创建太多。
短文档字符串应是名副其实的单行句子
# bad def reverse_sort(items): """ sort items in reverse order """ # good def reverse_sort(items): """Sort items in reverse order."""把三引号 “”” 放在同一行,首字母大写,以句号结尾。四行精简到两行,doc 属性没有糟糕的换行,最吹毛求疵的人也会满意的! 文档字符串使用 reST
标准库和大多数开源项目皆是如此。Sphinx 提供支持,开箱即用。赶紧试试吧!Python requests 模块由此取得了极佳的效果。看看requests.api 模块的例子。 删除结尾空格
最挑剔也不过如此了吧,可是若做不到这一点,有些人可能会被逼疯。不乏能自动搞定这一切的编辑器;这是我用 vim 的实现。 文档字符串要写好
下面是在函数文档字符串中使用 Sphinx 风格的 reST 的快速参考:
def get(url, qsargs=None, timeout=5.0): """Send an HTTP GET request. :param url: URL for the new request. :type url: str :param qsargs: Converted to query string arguments. :type qsargs: dict :param timeout: In seconds. :rtype: mymodule.Response """ return request('get', url, qsargs=qsargs, timeout=timeout) >>> 不要为文档而写文档。写文档字符串要这样思考: >>> 好名字 + 显式指明默认值 优于 罗嗦的文档 + 类型的详细说明也就是说,上例中没有必要说 timeout 是 float,默认值 5.0,显然是 float。在文档中指出其语义是「秒」更有用,就是说 5.0 意思是 5 秒钟。同时调用方不知道 qsargs 应该是什么,所以用 type 注释给出提示,调用方也无从知道函数的预期返回值是什么,所以 rtype注释是合适的。
最后一点。吉多·范罗苏姆曾说过,他对 Python 的主要领悟是「读代码比写代码频率更高」。直接结论就是有些文档有用,更多的文档有害。
基本上只需要给预计会频繁重用的函数写文档。如果给内部模块的每一个函数都写上文档,最后只能得到更加难以维护的模块,因为重构代码之时文档也要重构。不要「船货崇拜」文档字符串,更不要用工具自动生成文档。 范式和模式 是函数还是类
通常应该用函数而不是类。函数和模块是 Python 代码重用的基本单元,还是最灵活的形式。类是一些 Python 功能的「升级路径」,比如实现容器,代理,描述符,类型系统等等。但是通常函数都是更好的选择。
或许有人喜欢为了更好地组织代码而将关联的函数归在类中。但这是错的。关联的函数应该归在模块中。
尽管有时可以把类当作「小型命名空间」(比如用 @staticmethod)比较有用,一组方法更应该对同一个对象的内部操作有所贡献,而不仅仅作为行为分组。
与其创建 TimeHelper 类,带有一堆不得不引入子类才能使用的方法,永远不如直接为时间相关的函数创建 lib.time 模块。类会增殖出更多的类,会增加复杂性,降低可读性。 生成器和迭代器
生成器和迭代器是 Python 中最强大的特性 —— 应该掌握迭代器协议,yield 关键字和生成器表达式。
生成器不仅仅对要在大型数据流上反复调用的函数十分重要,而且可以让自定义迭代器更加简单,从而简化了代码。将代码重构为生成器通常可以在使得代码在更多场景下复用,从而简化代码。
Fluent Python 的作者 Lucinao Ramalho 通过 30 分钟的演讲,「迭代器和生成器: Python 之道」,给出了一个出色的,快节奏的概述。Python Essential Reference 和 Python Cookbook 的作者 David Beazley 有个深奥的三小时视频教程,「生成器:最后的前沿」,给出了令人满足的生成器用例的详细阐述。因为应用广泛,掌握这一主题非常有必要。 声明式还是命令式
声明式编程优于命令式编程。代码应该表明你想要做什么,而不是描述如何去做。Python 的函数式编程概览介绍了一些不错的细节并给出了高效使用该风格的例子。
使用轻量级的数据结构更好,比如 列表,字典,元组和集合。将数据展开,编写代码对其进行转换,永远要优于重复调用转换函数/方法来构建数据。
「纯」函数和迭代器更好
这是个从函数式编程社区借来的概念。这种函数和迭代器亦被描述为「无副作用」,「引用透明」或者有「不可变输入/输出」。 一个简单的例子,要避免这种代码:
# bad def dedupe(items): """Remove dupes in-place, return items and # of dupes.""" seen = set() dupe_positions = [] for i, item in enumerate(items): if item in seen: dupe_positions.append(i) else: seen.add(item) num_dupes = len(dupe_positions) for idx in reversed(dupe_positions): items.pop(idx) return items, num_dupes # good def dedupe(items): """Return deduped items and # of dupes.""" deduped = set(items) num_dupes = len(items) - len(deduped) return deduped, num_dupes这是个惊人的例子。函数不仅更加纯粹,而且更加精简了。不仅更加精简,而且更好。这里的纯粹是说 assert dedupe(items) == dedupe(items) 在「好」版本中恒为真。在「坏」版本中, num_dupes 在第二次调用时恒为 0,这会在使用时导致难以理解的错误。
这个例子也阐明了命令式风格和声明式风格的区别:改写后的函数读起来更像是对需要的东西的描述,而不是构建需要的东西的一系列操作。 简单的参数和返回值类型更好
函数应该尽可能处理数据,而不是自定义的对象。简单的参数类型更好,比如字典,集合,元组,列表,int,float 和 bool。从这些扩展到标准库类型,比如 datetime, timedelta, array, Decimal 以及 Future。只有在真的必要时才使用自定义类型。
判断函数是否足够精简有个不错的经验法则,问自己参数和返回值是否总是可以 JSON 序列化。结果证明这个经验法则相当有用:可以 JSON 序列化通常是函数在并行计算时可用的先决条件。但是,就本文档而言,主要的好处在于:可读性,可测试性以及总体的函数简单性。 避免「传统的」面向对象编程
在「传统的面向对象编程语言」中,比如 Java 和 C++ ,代码重用是通过类的继承和多态或者语言声称的类似机制实现的。对 Python 而言,尽管可以使用子类和基于类的多态,事实上在地道的 Python 程序中这些功能极少使用。
通过模块和函数实现代码重用更为普遍,通过鸭子类型实现动态调度更为常见。如果发现自己通过超类实现代码重用,停下来,重新思考。如果发现自己大量使用多态,考虑一下是否用 Python 的 dunder 协议或者鸭子类型策略会更好。
看一下另一个不错的 Python 演讲,一位 Python 核心贡献者的 「不要再写类了」。演讲者建议,如果构建的类只有一个命名像一个类的方法(比如 Runnable.run()),那么实际上只是用函数模拟了一个类,这时候应该停下来。因为在 Python 中,函数是「最高级的」类型,没有理由这样做。
Mixin 有时也没问题
可以使用 Mixin 实现基于类的代码重用,同时不需要走极端使用类型层次。但是不要滥用。「扁平胜于嵌套」也适用于类型层次,所以应该避免仅仅为了分解行为而引入不必要的必须层次的一层。
Mixin 实际上不是 Python 的特性,多亏了 Python 支持多重继承。可以创建基类将功能「注入」到子类中,而不必构成类型层次的「重要」组成部分,只需要将基类列入 bases列表中的第一个元素。
class APIHandler(AuthMixin, RequestHandler): """Handle HTTP/JSON requests with security."""要考虑顺序,同时不妨记住:bases 自底向上构成层次结构。这里可读性的好处在于关于这个类所需要知道的一切都包含在类定义本身:「它混入了权限行为,是专门定制的 Tornado RequestHandler。」
-
Semantic Segment
LeNet 网络结构
论文 | Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation
前言
临近春节,Google 团队也不休假,趁着中国人每年一度大迁徙,他们在 arXiv 放出了 DeepLabv3+,在语义分割领域取得新的 state-of-the-art 水平。本文将带大家回顾 DeepLabv1-v4 系列的发展历程,看看 Google 团队这些年都在做什么。
DeepLabv1
DeepLab 是结合了深度卷积神经网络(DCNNs)和概率图模型(DenseCRFs)的方法。
在实验中发现 DCNNs 做语义分割时精准度不够的问题,根本原因是 DCNNs 的高级特征的平移不变性,即高层次特征映射,根源于重复的池化和下采样。
针对信号下采样或池化降低分辨率,DeepLab 是采用的 atrous(带孔)算法扩展感受野,获取更多的上下文信息。
分类器获取以对象中心的决策是需要空间变换的不变性,这天然地限制了 DCNN 的定位精度,DeepLab 采用完全连接的条件随机场(CRF) 提高模型捕获细节的能力。
除空洞卷积和 CRFs 之外,论文使用的 tricks 还有 Multi-Scale features。其实就是 U-Net 和 FPN 的思想,在输入图像和前四个最大 池化层的输出上附加了两层的 MLP,第一层是 128 个 3×3 卷积,第二层是 128 个 1×1 卷积。最终输出的特征与主干网的最后一层特征图 融合,特征图增加 5×128=640 个通道。
实验表示多尺度有助于提升预测结果,但是效果不如 CRF 明显。
论文模型基于 VGG16,在 Titan GPU 上运行速度达到了 8FPS,全连接 CRF 平均推断需要 0.5s ,在 PASCAL VOC-2012 达到 71.6% IOU accuracy。
DeepLabv2
DeepLabv2 是相对于 DeepLabv1 基础上的优化。DeepLabv1 在三个方向努力解决,但是问题依然存在:特征分辨率的降低、 物体存在多尺度,DCNN 的平移不变性。
因 DCNN 连续池化和下采样造成分辨率降低,DeepLabv2 在最后几个最大池化层中去除下采样,取而代之的是使用空洞卷积, 以更高的采样密度计算特征映射。
物体存在多尺度的问题,DeepLabv1 中是用多个 MLP 结合多尺度特征解决,虽然可以提供系统的性能,但是增加特征计算量和存储空间。
论文受到 Spatial Pyramid Pooling (SPP) 的启发,提出了一个类似的结构,在给定的输入上以不同采样率的空洞卷积并行采样, 相当于以多个比例捕捉图像的上下文,称为 ASPP (atrous spatial pyramid pooling) 模块。
DCNN 的分类不变形影响空间精度。DeepLabv2 是采样全连接的 CRF 在增强模型捕捉细节的能力。
论文模型基于 ResNet,在 NVidia Titan X GPU 上运行速度达到了 8FPS,全连接 CRF 平均推断需要 0.5s ,在耗时方面和 DeepLabv1 无差异, 但在 PASCAL VOC-2012 达到 79.7 mIOU。
DeepLabv3
好的论文不止说明怎么做,还告诉为什么。DeepLab 延续到 DeepLabv3 系列,依然是在空洞卷积做文章,但是探讨不同结构的方向。
DeepLabv3 论文比较了多种捕获多尺度信息的方式:

-
Image Pyramid:将输入图片放缩成不同比例,分别应用在 DCNN 上,将预测结果融合得到最终输出。
-
Encoder-Decoder:利用 Encoder 阶段的多尺度特征,运用到 Decoder 阶段上恢复空间分辨率,代表工作有 FCN、SegNet、PSPNet 等工。
-
Deeper w. Atrous Convolution:在原始模型的顶端增加额外的模块,例如 DenseCRF,捕捉像素间长距离信息。
-
Spatial Pyramid Pooling:空间金字塔池化具有不同采样率和多种视野的卷积核,能够以多尺度捕捉对象。
DeepLabv1-v2 都是使用带孔卷积提取密集特征来进行语义分割。但是为了解决分割对象的多尺度问题,DeepLabv3 设计采用多比例的带孔卷积级联或 并行来捕获多尺度背景。
此外,DeepLabv3 将修改之前提出的带孔空间金字塔池化模块,该模块用于探索多尺度卷积特征,将全局背景基于图像层次进行编码获得特征,取得 state-of-art 性能,在 PASCAL VOC-2012 达到 86.9 mIOU。
DeepLabv3+
DeepLabv3+ 架构
DeepLabv3+ 继续在模型的架构上作文章,为了融合多尺度信息,引入语义分割常用的 encoder-decoder。在 encoder-decoder 架构中,引入可 任意控制编码器提取特征的分辨率,通过空洞卷积平衡精度和耗时。
在语义分割任务中采用 Xception 模型,在 ASPP 和解码模块使用 depthwise separable convolution,提高编码器-解码器网络的运行速率和 健壮性,在 PASCAL VOC 2012 数据集上取得新的 state-of-art 表现,89.0 mIOU。

Xception 改进
Entry flow 保持不变,但是添加了更多的 Middle flow。所有的 max pooling 被 depthwise separable convolutions 替代。 在每个 3x3 depthwise convolution 之外,增加了 batch normalization 和 ReLU。
实验
论文提出的模型在主干网络 ResNet-101 和 Xception均进行验证。两种方式均在 ImageNet 预训练。其中 Xception 预训练过程中, 使用 50 个 GPU,每个 GPU batch size=32,分辨率 299x299。Xception 相比 ResNet-101,在 Top-1 和 Top-5 分别提高 0.75% 和 0.29%。

在实验过程中,分别考虑 train OS: The output stride used during training、eval OS: The output stride used during evaluation、Decoder: Employing the proposed decoder structure、MS: Multi-scale inputs during evaluation、 Flip: Adding left-right flipped inputs 等各种情况。

另外使用 depthwise separable convolution,使用 Pretraining on COCO 和 Pretraining on JFT,在这些 tricks 辅助下, PASCAL VOC 2012 test set 达到惊人的 89.0%,取得新的 state-of-the-art 水平。

结论
从 DeepLabv1-v4 系列看,空洞卷积必不可少。从 DeepLabv3 开始去掉 CRFs。
Github 目前还未有公布的 DeepLabv3,但是有网友的复现版本。DeepLabv3+ 更是没有源代码,复现起来估计有些难度。
DeepLabv3 复现:
https://github.com/NanqingD/DeepLabV3-Tensorflow
DeepLabv1-v4 没有用很多 tricks,都是从网络架构中调整,主要是如何结合多尺度信息和空洞卷积。从FCN,ASPP,Encoder-Decoder with Atrous Conv,每一个想法看上去在别的都实现过,但是论文综合起来就是有效。
Deeplabv1,v2 耗时为 8fps,从 Deeplabv3 开始,论文已经不说运行时间的问题,是否模型越来越慢了。
MobileNetV2 已经实现 Deeplabv3,并努力在 MobileNetV2 中复现 DeepLabv3+ 版本。
参考文献
[1] Semantic image segmentation with deep convolutional nets and fully connected CRFs.
[2] DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs.
[3] Rethinking Atrous Convolution for Semantic Image Segmentation.
[4] Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation.
-
-
LeNet 网络结构
前言
LeNet5通过巧妙的设计,利用卷积、参数共享、池化等操作提取特征,避免了大量的计算成本,最后再使用全连接神经网络进行分类识别,这个网络是卷积神经网络架构的起点,后续许多网络都以此为范本进行优化。Lenet 是一系列网络的合称,包括 Lenet1 - Lenet5,由 Yann LeCun 等人在 1990 年《Handwritten Digit Recognition with a Back-Propagation Network》中提出,是卷积神经网络的 HelloWorld。
一、Lenet5网络结构
Lenet是一个 7 层的神经网络,包含 3 个卷积层,2 个池化层,1 个全连接层。其中所有卷积层的所有卷积核都为 5x5,步长 strid=1,池化方法都为全局 pooling,激活函数为 Sigmoid,网络结构如下:
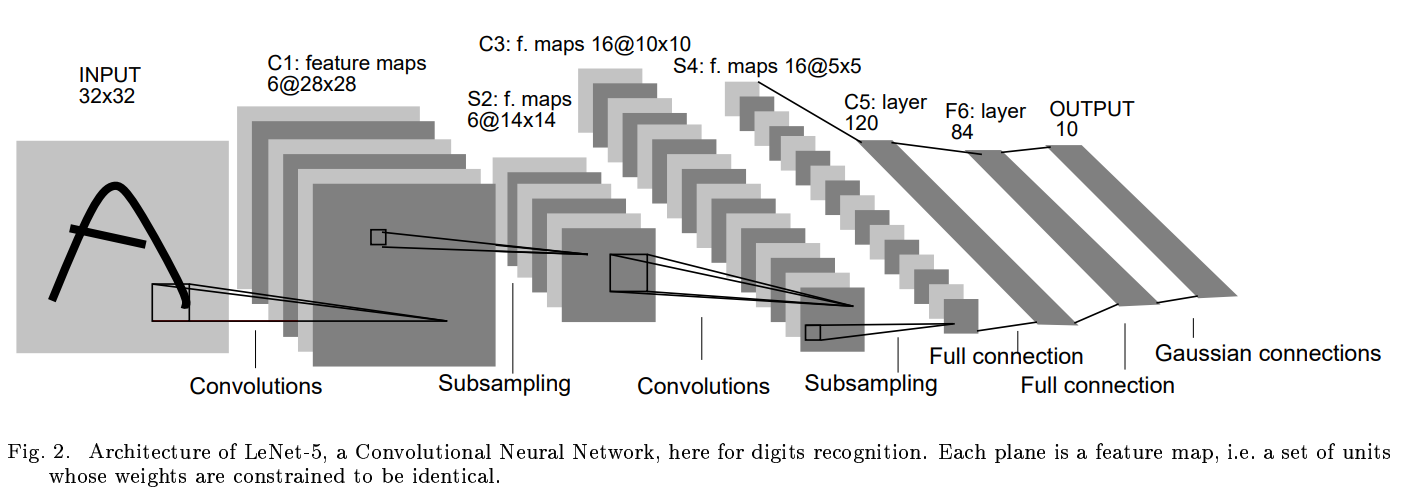
特点:
1.相比MLP,LeNet使用了相对更少的参数,获得了更好的结果。
2.设计了maxpool来提取特征
二、Lenet的keras实现
如今各大深度学习框架中所使用的LeNet都是简化改进过的LeNet-5,和原始的LeNet有些许不同,把激活函数改为了现在很常用的ReLu。LeNet-5跟现有的conv->pool->ReLU的套路不同,它使用的方式是conv1->pool->conv2->pool2再接全连接层,但是不变的是,卷积层后紧接池化层的模式依旧不变。
def LeNet(): model = Sequential() # 原始的Lenet此处卷积核数量为6,且激活函数为线性激活函数 model.add(Conv2D(32, (5,5), strides=(1,1), input_shape=(28,28,1), padding='valid', activation='relu', kernel_initializer='uniform')) model.add(MaxPooling2D(pool_size=(2,2))) # 原始的Lenet此处卷积核数量为16,且激活函数为线性激活函数 model.add(Conv2D(64, (5,5), strides=(1,1), padding='valid', activation='relu', kernel_initializer='uniform')) model.add(MaxPooling2D(pool_size=(2,2))) model.add(Flatten()) model.add(Dense(100, activation='relu')) model.add(Dense(10, activation='softmax')) return model三、Lenet的pytorch实现
import torch import torch.nn as nn import torch.nn.functional as F class LeNet5(nn.Module): def __init__(self, num_classes, grayscale=False): """ num_classes: 分类的数量 grayscale: 是否为灰度图 """ super(LeNet5, self).__init__() self.grayscale = grayscale self.num_classes = num_classes if self.grayscale: # 可以适用单通道和三通道的图像 in_channels = 1 else: in_channels = 3 # 卷积神经网络 self.features = nn.Sequential( nn.Conv2d(in_channels, 6, kernel_size=5), nn.MaxPool2d(kernel_size=2), nn.Conv2d(6, 16, kernel_size=5), nn.MaxPool2d(kernel_size=2) # 原始的模型使用的是 平均池化 ) # 分类器 self.classifier = nn.Sequential( nn.Linear(16*5*5, 120), # 这里把第三个卷积当作是全连接层了 nn.Linear(120, 84), nn.Linear(84, num_classes) ) def forward(self, x): x = self.features(x) # 输出 16*5*5 特征图 x = torch.flatten(x, 1) # 展平 (1, 16*5*5) logits = self.classifier(x) # 输出 10 probas = F.softmax(logits, dim=1) return logits, probas if __name__ == "__main__": num_classes = 10 # 分类数目 grayscale = True # 是否为灰度图 data = torch.rand((1, 1, 32, 32)) print("input data:\n", data, "\n") model = LeNet5(num_classes, grayscale) logits, probas = model(data) print("logits:\n",logits) print("probas:\n",probas)
-
Gitlab 仓库迁移
生产环境上迁移GitLab的目录需要注意一下几点:
- 目录的权限必须为755或者775
- 目录的用户和用户组必须为git:git
- 如果在深一级的目录下,那么git用户必须添加到上一级目录的账户。
- 很多文章说修改/etc/gitlab/gitlab.rb这个文件里面的
git_data_dirsb变量,其实没必要,只需要使用软链接改变原始目录/var/opt/gitlab/git-data更好一些. - 注意:迁移前的版本和迁移后的版本必须保持一致, 如果迁移后的版本是高版本, 那么现在原版本做升级后再迁移.
迁移方法:
# 停止服务 gitlab-ctl stop # 备份目录 mv /var/opt/gitlab/git-data{,_bak} # 新建新目录 mkdir -p /data/service/gitlab/git-data # 设置目录权限 chown -R git:git /data/service/gitlab chmod -R 775 /data/service/gitlab # 同步文件,使用rsync保持权限不变 rsync -av /var/opt/gitlab/git-data_bak/repositories /data/service/gitlab/git-data/ # 创建软链接 ln -s /data/service/gitlab/git-data /var/opt/gitlab/git-data # 更新权限 gitlab-ctl upgrade # 重新配置 gitlab-ctl reconfigure # 启动gitlab服务 gitlab-ctl start
-
Cblas-Lapack-Linux-Lib
Linux 安装 cblas, lapack, lapacke
1 确保机器上安装了gfortran编译器,如果没有安装的话,可以使用sudo apt-get install gfortran
2 下载blas, cblas, lapack 源代码, 这些源码都可以在 http://www.netlib.org 上找到,下载并解压。这里提供我安装时的下载链接.解压之后会有三个文件夹,BLAS, CBLAS, lapack-3.4.2
blas cblas lapack
3 这里就是具体的编译步骤
编译blas, 进入BLAS文件夹,执行以下几条命令
gfortran -c -O3 *.f # 编译所有的 .f 文件,生成 .o文件 ar rv libblas.a *.o # 链接所有的 .o文件,生成 .a 文件 sudo cp libblas.a /usr/local/lib # 将库文件复制到系统库目录编译cblas, 进入CBLAS文件夹,首先根据你自己的计算机平台,将目录下某个 Makefile.XXX 复制为 Makefile.in , XXX表示计算机的平台,如果是Linux,那么就将Makefile.LINUX 复制为 Makefile.in,然后执行以下命令
cp ../BLAS/libblas.a testing # 将上一步编译成功的 libblas.a 复制到 CBLAS目录下的testing子目录 make # 编译所有的目录 sudo cp lib/cblas_LINUX.a /usr/local/lib/libcblas.a # 将库文件复制到系统库目录下编译 lapack以及lapacke,这一步比较麻烦,首先当然是进入lapack-3.4.2文件夹,然后根据平台的特点,将INSTALL目录下对应的make.inc.XXX 复制一份到 lapack-3.4.2目录下,并命名为make.inc, 这里我复制的是 INSTALL/make.inc.gfortran,因为我这里用的是gfortran编译器。
修改lapack-3.4.2/Makefile, 因为lapack以来于blas库,所以需要做如下修改
# lib: lapacklib tmglib lib: blaslib variants lapacklig tmglib make # 编译所有的lapack文件 cd lapacke # 进入lapacke 文件夹,这个文件夹包含lapack的C语言接口文件 make # 编译lapacke cp include/*.h /usr/local/include # 将lapacke的头文件复制到系统头文件目录 cd .. #返回到 lapack-3.4.2 目录 cp *.a /usr/local/lib # 将生成的所有库文件复制到系统库目录这里的头文件包括:
lapacke.h, lapacke_config.h, lapacke_mangling.h, lapacke_mangling_with_flags.h lapacke_utils.h生成的库文件包括:
liblapack.a, liblapacke.a, librefblas.a, libtmglib.a至此cblas和lapack就成功安装到你的电脑上了。
测试:
可以到 LAPACKE 找测试代码,这里是lapacke的官方文档,比如以下代码:
/* Calling DGELS using row-major order: gfortran test.c -llapacke -llapack */ #include <stdio.h> #include <lapacke.h> int main (int argc, const char * argv[]) { double a[5*3] = {1,2,3,4,5,1,3,5,2,4,1,4,2,5,3}; double b[5*2] = {-10,12,14,16,18,-3,14,12,16,16}; lapack_int info,m,n,lda,ldb,nrhs; int i,j; m = 5; n = 3; nrhs = 2; lda = 5; ldb = 5; info = LAPACKE_dgels(LAPACK_COL_MAJOR, 'N', m, n, nrhs, a, lda, b, ldb); for(i=0;i<n;i++) { for(j=0;j<nrhs;j++) { printf("%lf ",b[i+ldb*j]); } printf("\n"); } return(info); }将上诉代码保存为test.c,编译时,别忘了使用gfortran,此外,还需要连接用到的库,编译上面的代码,应使用如下命令:
gfortran test.c -llapacke -llapack -lrefblas如果能正常编译,即表示安装成功。如果要了解这段代码的具体含义,可以到 LAPACKE 查看. Fork-Address